Saurav Singh damngamerz
Phase 1 Month End Summary
Hi Guys!, How you doing?
It’s been 4 weeks of CODING PHASE-I and it’s evaluation time. So from 26th 9:30pm, Evaluation links will become active both me and my mentor have to fill a Q & A form ^_^. I will tell you more about it in a while, but first I will be sumarizing my GSoC’2017’s work of last 2 weeks. So, let’s begin!!
Summary
The deadline of achieving the milestones set by my organization is 26th June. Following are the issues on which I have worked upon in last 2 weeks:
- In python we have triple quoted string literals. Eg:
dummy_variable = """ This is a triple quoted string literal and is not a docstring. """This needs to be ignored, as it’s not a docstring. The solution to this was pretty simple, we made sure that starting marker (i.e.
marker[0]) should only be followed by an indentation, so as to consider it a valid docstring. Hence I completed the work over this and a patch is submitted and merged. parse()member function ofDocumentationCommentwas breaking if we miss an ending colon in the docstring. Eg:def foobar(param1, param2): """ This is a dummy function. :param param1: ending colon is present :param param2 ending colon is missing :return: nothing """ return NoneWe first began to find a solution by adding
self.errorsinDocumentationComment’s__init__which will return a list of raised errors to the bear, so that it yields aRESULTwith a beautiful message. Though this worked but was not an appropriate way to handle exceptions. You might be thinking why not directlyraisean appropriate exception from theDocumentationComment? Well, If you look carefully about working ofcoalait runs the bear as ageneratorand yeilds aRESULTif it finds something inappropiate. Our sole aim was to keep thegeneratorrunning, so if we raise anExceptioninsideDocumentationCommentthe generator will be terminated andcoalawon’t run further to find any other docstring. Second way was to yield something likeMalformedCommentinstead ofDocumentationComment. This seems a good idea but it would require a lot of ideation. AlsoDocumentationExtractionyieldsDocumentationCommentand we can’t make it out anywhere just after the extraction that the docstring is malformed. So what was the solution? Lately, I noticed why the parser was breaking. There was anIndexErrorat the position where we spitted the parameter’s name and description. So the fix was to check either for ending marker or for a space so as to split the parameter’s name and a description. And Viola!! This worked!! Although I still feel likeDocumentationAPIneeds to have a separateExceptionclass. Anyway patch submitted and merged
Also, 2 Issues are moved ahead to PHASE-II. We feel like it’s better to solve them after the implementation of DocBaseClass().
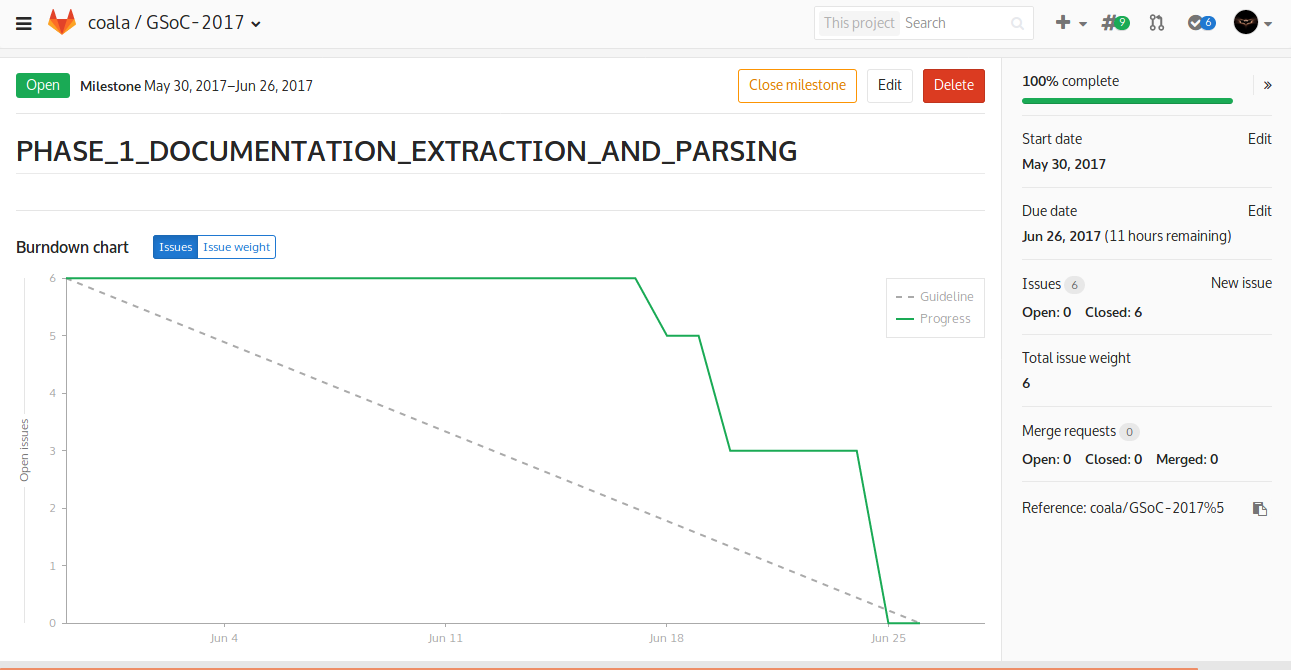
This was it!! I achieved my milestone of PHASE-I. You can see my progress here. And here’s how my burndown chart looks like.
 feelsgoodman!! ^_^
feelsgoodman!! ^_^
Thanks!!
Thanks and Congrats to…. Ofcourse, both of my mentors SanketDG & NiklasMM for achieving this milestone together. We still have 2 more on the uproad to go through ;)
Special Thanks to Makman2. He helped me alot initially, with some of the issues and also reviewed my patches.
What’s up next?
Next up after the evaluation is CODING PHASE-II. In which our sole aim is to implement a DocBaseClass and then use it in our existing DocStyleBear.
EuroPython Update.
Yass bois!! Im going to attend EP’2017. Got my VISA approved YAY!! July is going to be one hell of a month.
That’s it for today. Till next time. See yaa!!
Written on June 26th, 2017 by Saurav Singh